It's the representation doing the work
cortex turns each cardholder's transaction sequence into a per-transaction hidden state — encoding the behavioral context (recency, merchant patterns, spend rhythm) that fraud teams normally chase with bespoke feature pipelines. The classifier and protocol are identical across lanes; only the features differ.
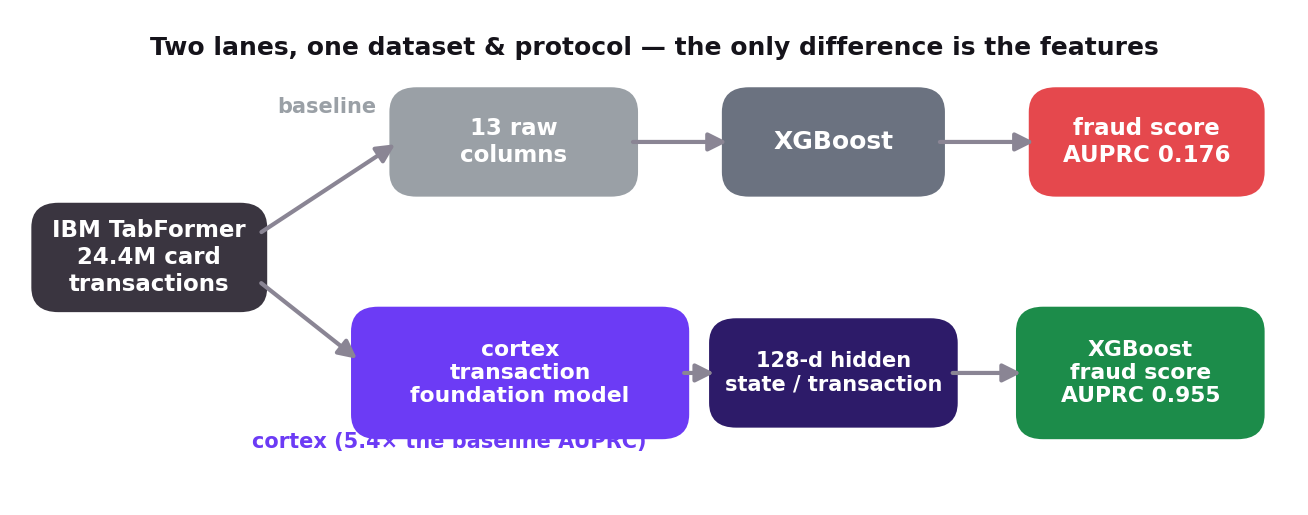
Results
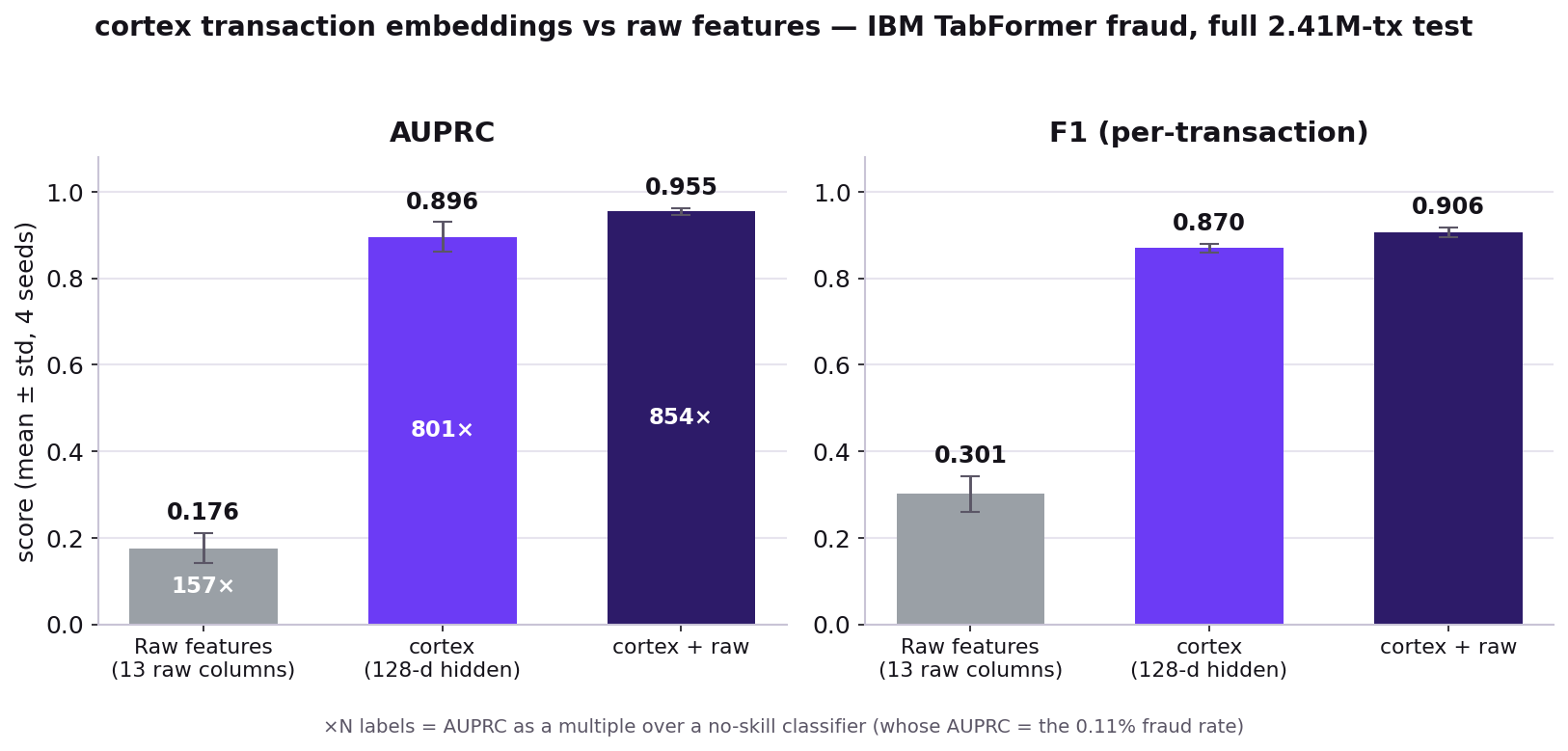
Per-transaction, on the entire held-out split (2,412,326 transactions, 2,698 fraud, 0.112%) — not a convenience sample. Training is balanced (all fraud + downsampled non-fraud), early-stopped on the full validation split. × random is the multiple over a no-skill classifier (whose AUPRC equals the fraud rate). Mean ± std over 4 seeds.
| Model | Features | AUPRC | × random | F1 |
|---|---|---|---|---|
| Raw features | 13 raw columns | 0.176 ± 0.034 | 157× | 0.301 ± 0.041 |
| cortex · pretrain | self-supervised · 128-d | 0.052 ± 0.010 | 46× | 0.070 ± 0.026 |
| cortex · pretrain + raw | raw + hidden | 0.187 ± 0.036 | 167× | 0.320 ± 0.033 |
| cortex · finetune | supervised · 128-d | 0.896 ± 0.034 | 801× | 0.870 ± 0.010 |
| cortex · finetune + raw | raw + hidden | 0.955 ± 0.007 | 854× | 0.906 ± 0.012 |
AUROC is omitted: at this prevalence it saturates near the ceiling for almost any model, so it can't separate good from great. AUPRC is the honest metric.
Self-supervised (pretrain)
With no fraud labels, the embedding alone (0.052) sits below the raw baseline — a decoder-style representation trades fine-grained tabular signal for sequential context. But fused with raw features it already edges ahead (0.187 vs 0.176): it adds behavioral signal the raw columns miss.
Supervised (finetune)
Let cortex see is_fraud during finetuning and the embedding becomes a standalone
fraud detector — 801× random on its own, 854× with
raw. The representation, not the classifier, is doing the work.
How this compares to NVIDIA's Transaction Foundation Model
NeoLDM grew up alongside NVIDIA's Transaction Foundation Model blueprint — same dataset, same idea (pretrain on raw transactions, use the embedding for downstream fraud). It's the natural reference point, so here's the honest picture.
| NVIDIA TFM | NeoLDM · cortex | |
|---|---|---|
| Backbone | Llama decoder (~29M), causal LM | cortex transaction FM |
| Embedding | 512-d last-token → 64-d PCA | 128-d hidden state |
| Downstream | XGBoost | XGBoost |
| Test set | 100K stratified subset | full 2.41M transactions |
| Published absolute metrics | none (notebook outputs not shipped) | full table above |
| Embedding alone vs raw | underperforms raw features (their notebook) | 0.896 — 5.1× the raw baseline (finetune) |
Not a same-protocol scoreboard — NVIDIA evaluates on a 100K stratified subset and publishes no absolute numbers, whereas every cortex figure here is on the full true test split. The blueprint's own conclusion is that its decoder embeddings lose to raw features alone; cortex reproduces that unsupervised, then a finetuned embedding stands on its own and beats the raw baseline 5.1×.
Run it yourself
Both notebooks render straight from the committed results — no GPU, dataset
download, or checkpoint required just to see the numbers. View the rendered output, or download
the .ipynb to run locally.
Raw-feature baseline
13 raw columns fed to XGBoost — the traditional approach (AUPRC 0.176, 157× random).
cortex embeddings
cortex hidden states fed to the same XGBoost (AUPRC 0.955, 854× random) and the lift over raw.
Dataset & embeddings
IBM TabFormer
The public credit-card-fraud dataset and conceptual ancestor of this line of work (arXiv:2011.01843, IBM/TabFormer). The raw CSV is fetched from IBM under IBM's terms — not redistributed here.
cortex embeddings
Per-transaction 128-d hidden states, published on Hugging Face: luizcoroo/cortex-ibm-tabformer-embeddings.